
2025 年 3 月現在では llms.txt は標準化されていない仕様です。この記事に書かれている内容は今後の変更により古くなる可能性があります。
ChatGPT や Grok, Claude, Gimini などの大規模言語モデルはますますウェブサイトの情報に依存してきています。特に最近登場した Deep Research はエージェント型のモデルがウェブサイトを巡回し、多段階のリサーチを自動で実行できるように設計されています。Deep Research が効果的に機能するためには AI エージェントが効率的にウェブサイトの情報を取得できることが重要です。
しかし従来のウェブサイトは人間向けのマークアップが主であり、AI ボットが情報を収集する際には多くの障壁があります。装飾のための CSS, 広告, 複雑な JavaScript などの要素は、本質的な情報の抽出を困難にしています。さらに、ウェブサイト運営者側からすると、AI エージェントによる過剰なスクレイピングがサーバー負荷を増大させるという新たな問題も浮上しています。
このような課題を解決し、LLM に最適化されたコンテンツを提供するために、Answer.AI の共同創業者である Jeremy Howard 氏により llms.txt という新しい標準ファイルが提案されました。
llms.txt とは
llms.txt は、シンプルかつ構造化されたマークダウン形式のファイルです。このフォーマットは人間と LLM の両方が容易に理解できるだけでなく、プログラムによる自動処理も可能な設計となっています。仕様ではウェブサイトのルートパス(/llms.txt)に配置することとされています。
このファイルにはウェブサイトの簡単な情報やガイダンスと詳細なマークダウンファイルへのリンクが含まれています。さらに LLM が読むのに役立つ情報を含むページには元のページの URL に .md を追加したマークダウン形式のファイルを提供することも提案されています。例えば https://azukiazusa.dev/blog/inline-conditional-css-if-function というブログ記事に対しては https://azukiazusa.dev/blog/inline-conditional-css-if-function.md というマークダウン形式のファイルを提供します。
提案には llms.txt と llms-full.txt という 2 つの異なるファイルがあります。
llms.txt: ウェブサイトのサマリー。詳細なページはマークダウン形式のファイルへのリンクで提供する。llms-full.txt: ウェブサイトの全てのページに関する情報を 1 つのファイルにまとめたもの。
llms-full.txt を提供している例として Cloudflare のドキュメントがあります。ドキュメントのすべての内容を 1 つのファイルにまとめているため、長大なテキスト量になっていることがわかりますね。
https://developers.cloudflare.com/llms-full.txt
llms.txt は既存のウェブ標準と共存するように設計されています。ファイルパスを標準化するアプローチは /robots.txt や /sitemap.xml のアプローチに従っています。ウェブサイトの情報を bot に提供するという点では robots.txt や sitemap.xml と同じ目的ですが、それぞれ異なる特徴を持ちます。
sitemap.xmlは検索エンジン向けのすべてのページのリストを提供する。一方でllms.txtは AI エージェント向けに厳選されたページのリストを提供する。robots.txtはどのページをクローラーが巡回してもよいかを伝えるが、ページのコンテキスト情報が含まれていない。llms.txtによりコンテキストを補完できる。robots.txtは定期的に巡回するクローラーに対してどのアクセスが許容されるかを制御する。llms.txtはユーザーが特定のトピックに関する情報を要求する場合にオンデマンドで使用される(llms.txtの普及が進めば通常のトレーニングでも使用される可能性がある)robots.txtとsitemap.xmlは検索エンジン向けに設計されているが、llms.txtは LLM 向けに設計されている
llms.txt の形式
llms.txt ファイルはマークダウン形式で記述します。これは現時点で言語モデルが最も理解しやすい形式であるためです。また llms.txt のマークダウンは特定の形式に従って書かれるため、プログラミング言語で処理することも可能です。
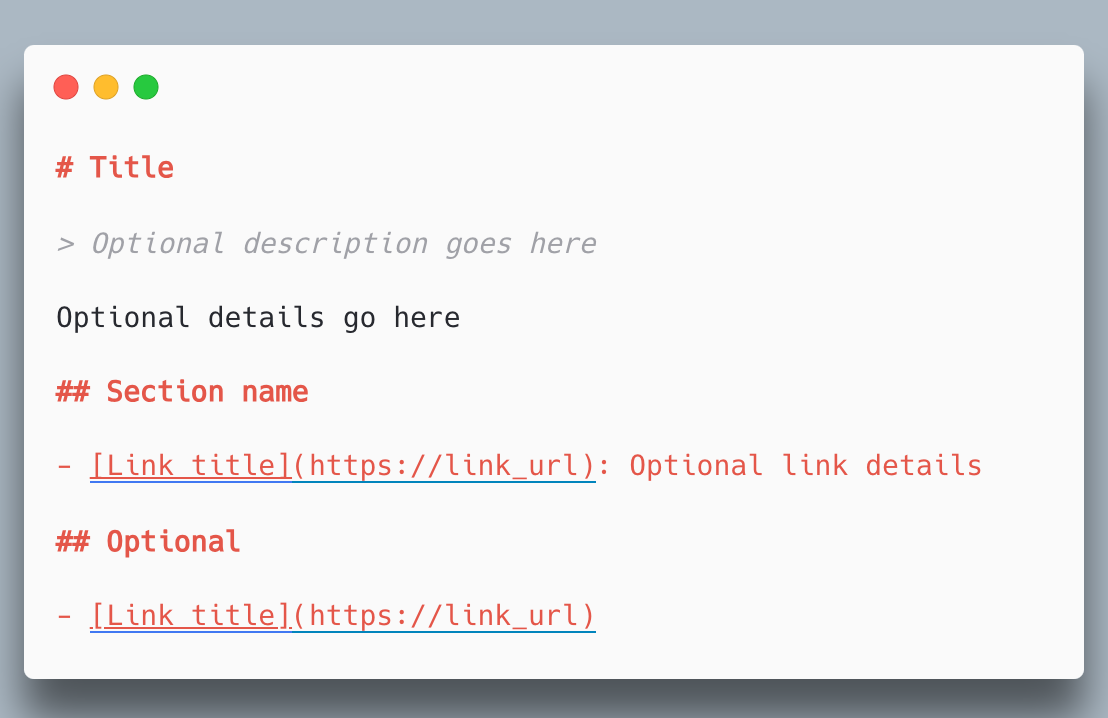
マークダウンには以下のセクションが含まれます。
- ウェブサイトの名前を記載した h1(
#)要素。必須のセクション - ウェブサイトの短い要約を含む引用(
>)ブロック - 0 個以上の見出しを除く任意のタイプのマークダウンセクション(段落、リストなど)
- 0 個以上の h2(
##)要素で区切られたセクション。詳細情報が含まれたマークダウンファイルへのリンクのリストを提供する- リンクのリストは
- [name](URL): descriptionの形式で記述する
- リンクのリストは
## Optionalで始まる特別なセクション。このセクションはスキップしても問題ない二次情報を提供する
llms.tsx ファイルの例は以下の通りです。
# My Website
> This is a website that provides information about various topics.
## Docs
- [Post 1](https://example.com/post1.md): This is the first post.
- [Post 2](https://example.com/post2.md): This is the second post.
## Optional
- [Forum](https://example.com/forum): A place to discuss topics.llms.txt を作成する
llms.txt ファイルを作成するためにはウェブサイト概要と各ページの詳細情報をまとめる llms.txt ファイル自身と各ページの詳細情報を含むマークダウンファイルを作成する必要があります。これらのページの作成を自動化するツールがいくつか提供されています。
- Mintlify — The documentation you want, effortlessly
- dotenvx/llmstxt: convert
sitemap.xmltollms.txt - Generate llms.txt
私の場合はツールを使って生成するメリットを感じなかったため、静的ビルドする際に記事の一覧を取得して作成するようにしました。簡単に実装例を紹介します。
前提として、このブログは SvelteKit で構築されていて Contentful から記事を取得してページを静的に生成しています。
SvelteKit では +server.ts ファイルで API ルートを定義します。export const prerender = true を宣言することにより、静的に API ルートを生成できます。src/routes/llms.tsx/+server.ts ファイルを作成して以下のように記述します(いくつか簡略化してコード例を示しています)。
import type { RequestHandler } from "@sveltejs/kit";
import RepositoryFactory, { POST } from "../../repositories/RepositoryFactory";
// PostRepository は Contentful から記事を取得する処理が書かれたクラス
const PostRepository = RepositoryFactory[POST];
export const prerender = true;
const siteUrl = "...";
type Item = {
title: string;
slug: string;
about: string;
};
// llms.txt の内容を生成する関数
const renderLlmsTxt = (items: Item[]) => `# azukiazusa のテックブログ2
> このブログは [azukiazusa](https://github.com/azukiazusa1) によって運営されている技術ブログです。主に Web フロントエンド周辺の技術について書いています。
## Blog Posts
${items
.map(
(item) =>
`- [${item.title}](${siteUrl}/blog/${item.slug}.md): ${item.about}`,
)
.join("\n")}
`;
// HTTP リクエスト Verb に対応する変数名を export することで API ルートとして認識される
export const GET: RequestHandler = async () => {
const posts = await PostRepository.findAll();
const feed = renderLlmsTxt(posts);
const headers = {
"Content-Type": "text/markdown; charset=utf-8",
};
return new Response(feed, {
headers,
});
};このあたりは rss.xml や sitemap.xml などのファイルを生成する場合と似たような手法で実装できますね。
各ブログ記事のマークダウンファイルも API ルートを作成して静的に生成します。src/routes/blog/[slug].md/+server.ts ファイルを作成して以下のように記述しました。
import type { RequestHandler } from "@sveltejs/kit";
import RepositoryFactory, {
POST,
} from "../../../repositories/RepositoryFactory";
const PostRepository = RepositoryFactory[POST];
export const prerender = true;
export const GET: RequestHandler = async ({ params }) => {
const { slug } = params;
const post = await PostRepository.find(slug);
if (!post) {
return new Response("Not found", { status: 404 });
}
const blogPost = post.blogPostCollection.items[0];
const body = `# ${blogPost.title}
${blogPost.article}
`;
return new Response(body, {
headers: {
"Content-Type": "text/markdown; charset=utf-8",
},
});
};http://azukiazusa.dev/llms.txt にアクセスすると生成されたファイルの内容が確認できます。
llms.txt の採用例
llms.txt もしくは llms-full.txt が提供されているウェブサイトは以下のリンクで確認できます。
AI エージェントから llms.txt を利用する
2025 年現在ではクローラーのように LLM が自動で llms.txt を検出してインデックスを作成することはありません。AI エージェントを利用するユーザーが手動で情報を提供する必要があります。
例えば AI コードエディタである Cursor では @docs シンボル機能により指定した URL を参照してより正確な回答を得ることができます。この際に llms-full.txt ファイルの URL を指定するといった使い方が考えられます。これにより AI エージェントが効率的に情報を取得できることが期待されます。


まとめ
- LLM がウェブサイトの情報を取得する際には
llms.txtというファイルが提案されている llms.txtとllms-full.txtという 2 つの異なるファイルがあるllms.txtはマークダウン形式で記述され、ウェブサイトの概要と各ページの詳細情報を提供するllms-full.txtはウェブサイトの全てのページに関する情報を 1 つのファイルにまとめたものllms.txtはウェブサイトのルートパスに配置されるllms.txtのマークダウンは以下のセクションを含む- ウェブサイトの名前を記載した h1(
#)要素 - ウェブサイトの短い要約を含む引用(
>)ブロック - 0 個以上の見出しを除く任意のタイプのマークダウンセクション
- 0 個以上の h2(
##)要素で区切られたセクション。詳細情報が含まれたマークダウンファイルへのリンクのリストを提供する ## Optionalで始まる特別なセクション
- ウェブサイトの名前を記載した h1(
参考
- The /llms.txt file – llms-txt
- AnswerDotAI/llms-txt: The /llms.txt file, helping language models use your website
- AI Agent時代なのでAWSのLLMs.txtが欲しい! - Speaker Deck
- このサイトで llms-full.txt を提供し始めた | Hirotaka Miyagi
- llms.txtを作るツールとして、Firecrawlをセルフホストで試す - nikkie-ftnextの日記
- LLMs.txt Explained | Towards Data Science



