
Firebase④ Cloud FireStore
Cloud FireStore(以下FireStore)とは、FireBaseの提供するドキュメント指向型 のNoSQLデータベースです。 NoSQLとしての特徴としてのスキーマレス、スケーラブルといった特徴のほかにリアルタイムアップデート、セキュリティルール、オフラインサポートといった独自の特徴を備えており、特にバックエンドを介さずにクライントサイドから直接操作できるという点が大きなポイントです。 また、β版から正式リリースされたのが2019年2月ということもあり、比較的新しい技術です。
Cloud FireStoreとは
Cloud FireStore(以下 FireStore)とは、FireBase の提供するドキュメント指向型 の NoSQL データベースです。 NoSQL としての特徴としてのスキーマレス、スケーラブルといった特徴のほかにリアルタイムアップデート、セキュリティルール、オフラインサポートといった独自の特徴を備えており、特にバックエンドを介さずにクライントサイドから直接操作できるという点が大きなポイントです。 またβ版から正式リリースされたのが 2019 年 2 月ということもあり、比較的新しい技術です。
RealTimeDatabaseとの違い
FireStore の登場時期がつい最近ということに触れましたが、FireStore が登場する以前はRealTimeDataBaseが使用されていました。FireStore は、RealTimeDatabase の特徴を受け継いだデータベースであり、RealTiemDatabase の弱点であったデータモデルを改善したりクエリを強化したりなどより使いやすくなっています。ですから、新たにプロジェクトを開始する場合にはほとんどの場合 FireStore を利用するべきです。
以下は、FireStore と RealTimeDatabase の比較です。
| RealTimeDatabase | FireStore | |
|---|---|---|
| データモデル | JSON | ドキュメントのコレクション |
| クエリ | ・制限あり(フィルタリングと並べ替えをの両方を同時に行うことはできない)・取得したデータのすべての子ノードを返す・JSONツリーの個々のノードまでアクセスできる・インデックスを必要としないが、データセットが大きくなるにつれて特定のクエリのパフォーマンスは低下する・ | ・一つのクエリでフィルタを組み合わせたり、フィルタリングと並べ替えを同時に行うことができる・特定のドキュメントまたはクエリのみを返し、サブコレクションを返さない・クエリは常にドキュメント全体を返す・クエリはデフォルトでインデックス付きになり、クエリのパフォーマンスは、データセットではなく、結果セットのサイズに比例する |
| セキュリティルール | 読み込みルールと書き込みルールはカスケード式に適応される | ワイルドカードを使用する場合を除き、ルールがカスケード式に適応されることはない |
| スケーラビリティ | スケーリングにはシャーディングが必要 | スケーリングは自動的に行われる |
| 課金 | 帯域幅とストレージにのみ課金され、課金レートは高くなる | 主な課金対象は、データベースで実行されているオペレーション(読み取り、書き込み、削除)、帯域幅、ストレージ。帯域幅とストレージへの課金レートは低く設定されてる |
FireStoreのデータモデル
FireStore は、MySQL や PostgreSQL などの SQL データベースと違い「テーブル」や「行」はありません。代わりに、データはドキュメントに格納され、それがコレクションとしてまとめられています。

ドキュメント
ドキュメントは、JSON とよく似たデータ構造です。 ブール値、文字列、数値、タイムスタンプ、配列、マップなどのなどのデータ型を持つ値を、キーバリューによってデータを保存します。 例えば、ユーザーを表すドキュメントは次のようになります。
name: {
firstName: '鈴木',
lastName: '太郎',
},
sex: 'male',
birthDay: 847694648,
favoriteFoods: ['寿司', 'ラーメン', '焼き肉']またドキュメントはスキーマレスであるため例えば同じユーザーを表すコレクションの中でも異なるデータ構造をもたせることができます。
name: '佐々木寿人',
birthDay: 847694648,
favoriteSongs: ['pretender', '紅蓮華', 'マリーゴールド']ただし、あまりに自由なデータ構造をもたせるとアプリケーションで扱いにくいデータになってしまうので、スキーマを定義したうえで使用するのが一般的です。スキーマレスな構造は、例えばレガシーなデータと互換性をもたせるために使われることがあります。
またドキュメントのデータサイズには制約があり、ドキュメント 1 剣あたりのサイズが 1MB までに制限されています。
ドキュメントはアプリケーションでそのまま扱えるように設計するのがポイントとなります。
コレクション
コレクションはドキュメントを格納するコンテナであり、すべてのドキュメントはコレクションの中に保存されます。
例えば、さきほどのドキュメントは Users コレクションに格納されることになります。
コレクション内のドキュメントの名前は一意である必要があり、独自のキーをしていするか Firestore で自動的にランダムな ID を振り分けることになります。
リファレンス
リファレンスは、ドキュメントが格納されているパスを表現するモデルで、データベースの場所によって一意に識別されます。
例えば、さきほどの Users コレクションにアクセスするためには、次のようなレファレンスを作成します。
users/jkfjakdfjaffahi@a
users/ahjioghja@gihjafu
またリファレンスはそのまま Firestore にデータとして保存できます。リファレンス型のデータの保存は、ドキュメント間の関係を表現する方法として利用されます。
サブコレクション
ドキュメントの階層構造を作るために、サブコレクションを利用できます。
サブコレクションはドキュメントの中にさらにコレクションを持つという構造になっており、ルートコレクションから見ると コレクション/ドキュメント/コレクション/ドキュメント といった構造になります。
サブコレクションはドキュメントの親子関係、所有/被所有を表現するためにしようされ、例えば ユーザー(Usres) と 記事(Articles) の関係は次のようになります。
users
jkfjakdfjaffahi@a
name: '鈴木太郎'
sex: 'male',
articles
fjlkafakjfafflakju
title: '記事1'
body: 'ここに内容が入ります'
published: false,
createdAt: 1560000000
ahjioghja@gihjafu
name: '佐々木寿人'
sex: 'male',
articles
lkafhja;kfhahgi
title: '記事2'
body: 'あいうえお'
published: true,
createdAt: 1460000000リファレンスは次のように表します。
users/fjlkafakjfafflakju/articles/fjlkafakjfafflakjuなぜサブコレクションを利用するのか
このデータ構造を見て、こんなふうに思ったほうもいるのではないのでしょうか。 「Firestore はそもそもデータ型としてリストやマップを備えているのだから、サブコレクションを利用しなくともそれらを利用すればよいのではないか」
つまり、次のようなデータ構造としても同じなのではないか、ということです。
users
jkfjakdfjaffahi@a
name: '鈴木太郎'
sex: 'male',
articles: [
{
id: fjlkafakjfafflakju
title: '記事1'
body: 'ここに内容が入ります'
published: false,
createdAt: 1560000000
}確かに、この構造はよく見慣れた JSON の構造であり、必要なデータを一度のクエリで取得できるというメリットもあります。 しかし、以下の点から基本的に階層データはサブコレクションで保持すべきです。
ドキュメントのデータサイズには制限がある
前出のとおり、ドキュメントのデータサイズは 1MB までという制限があります。通常の利用には問題ないのですが、上記の例のようにドキュメントのリストやマップにネストした構造は、ユーザーの操作とともに数が増えていくようなデータを保持するには適していません。
クエリ上の観点
FireStore でのドキュメントに対するクエリは、常にドキュメント全体を返します。 つまり、上記のデータ構造でユーザーデータを取得するとき、必要がないときでも常に記事のデータを取得しなければいけないため、クエリのサイズが大きくなり問題となります。
ドキュメントを取得するときに、通常その下の階層にあるサブコレクションは取得されません。サブコレクションは必要なときだけ取得すればよいことになります。
セキュリティルール上の観点
後述しますが、セキュリティルールを設計する際にもネストしたマップやリストを利用している場合問題が生じます。
セキュリティルールでは、for 文や一時変数が利用できないため、リストの要素数がドキュメントごとに異なっていたり、ネストしたマップの型が統一されていない場合は安全なスキーマ検証ができなくなります。
さらに、データの秘匿に関しても問題になります。 例えば、ユーザーのデータには公開してもよいデータ(名前、プロフィール)と他人には隠しておきたいが、本人は参照したいデータ(メールアドレス、住所)があるはずです。
以上のような問題は、サブコレクションによって解決されます。 サブコレクションは JSON ツリー型でしかデータを保持できなかった RealTimeDatabase の弱点を克服した構造ともいえるでしょう。
コレクショングループ
さらに、サブコレクションを利用する利点としてコレクショングループを利用できるという点が上げられます。
コレクショングループは、同一の ID をもつサブコレクションを 1 つのコレクションとみなして扱うことができる機能です。
通常のクエリでは、Users のサブコレクションである Articles を取得するには、users/{uid}/articles としてアクセスします。
ユーザーに紐づくすべての記事を取得するには単純ですが、
すべての記事を横断して取得するためにはユーザーごとの記事を取得する必要がありました。
しかし、コレクショングループを利用すれば、階層化されたサブコレクションを一度に取得できます。
コレクショングループクエリを使用するためには、コレクショングループクエリをサポートするインデックスを作成する必要があります。 さらに、ウェブとモバイル SDK の場合は、コレクショングループクエリを許可するルールも作成する必要があります。
ドキュメントのデータ型
FireStore のドキュメントには、以下のデータ型がサポートされています。
- 配列(リスト)
- ブール値
- バイト
- 日時
- 浮動小数点数
- 地理的座標
- 整数
- マップ
- null
- 参照(リファレンス)
- テキスト文字列
FireStoreを使ってみる
Firebase の概要についてここまで説明してきました。 ここからは、実際に FireStore を使いながら進めていきます。
データベースを有効化する
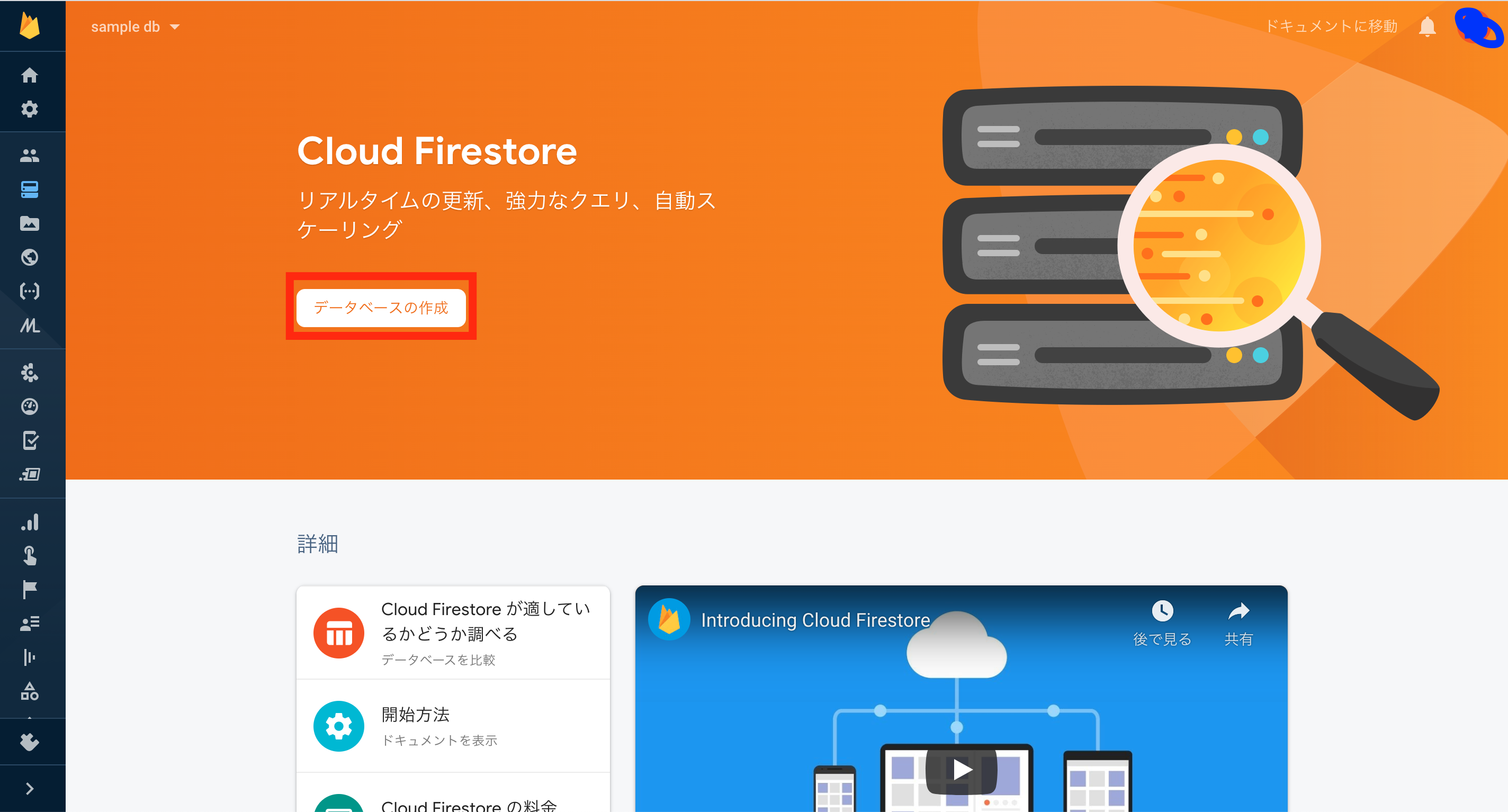
Firebase のプロジェクトを作成したら、左のナビゲーションバーから Database を選択します。

データベースの作成をクリックして、テストモードを選択しましょう。
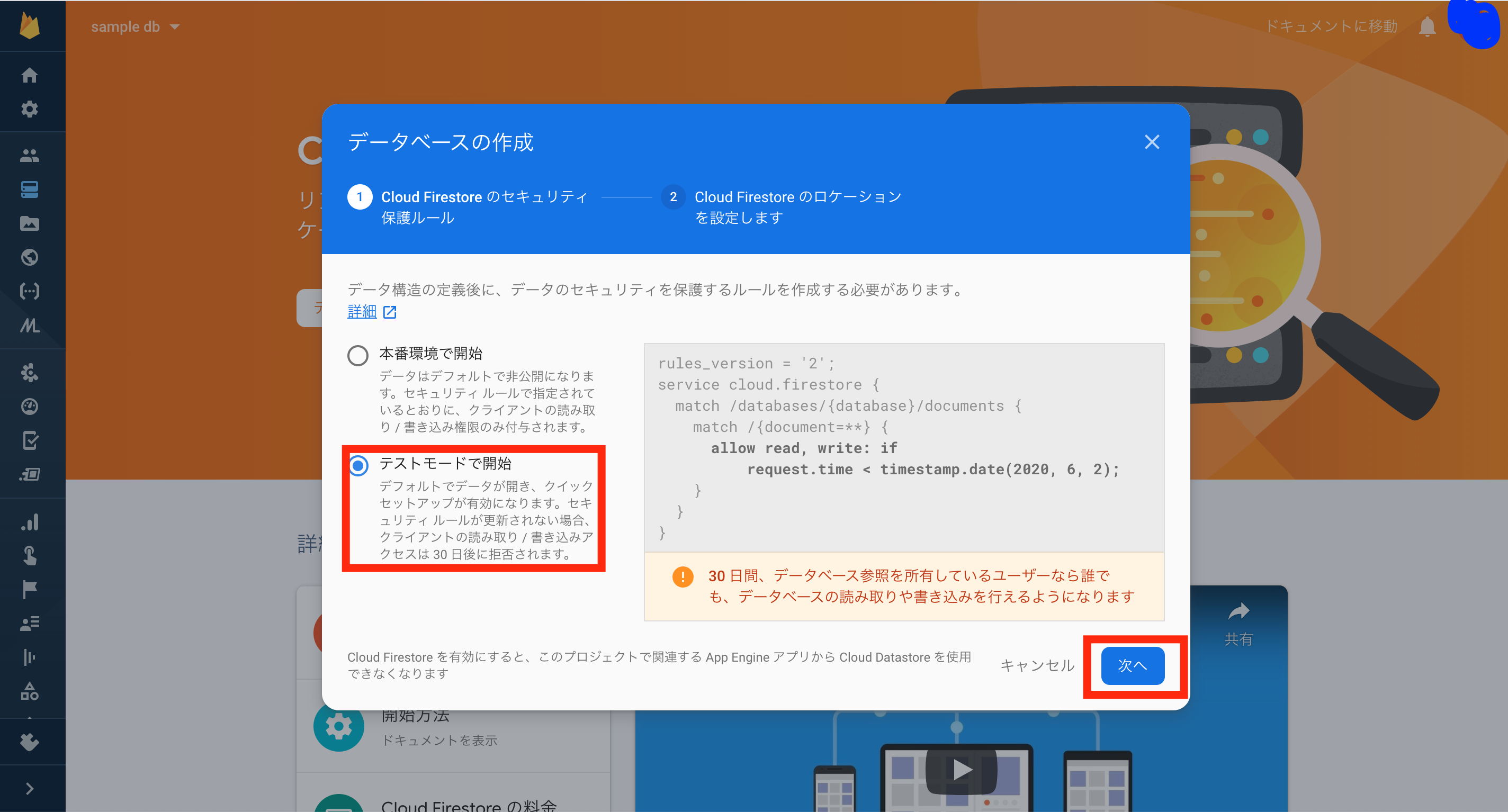
テストモードは、誰でもデータベースの読み取りや書き込みが行える状態であるため、決してテストモードのまま本番環境で使用してはいけません。
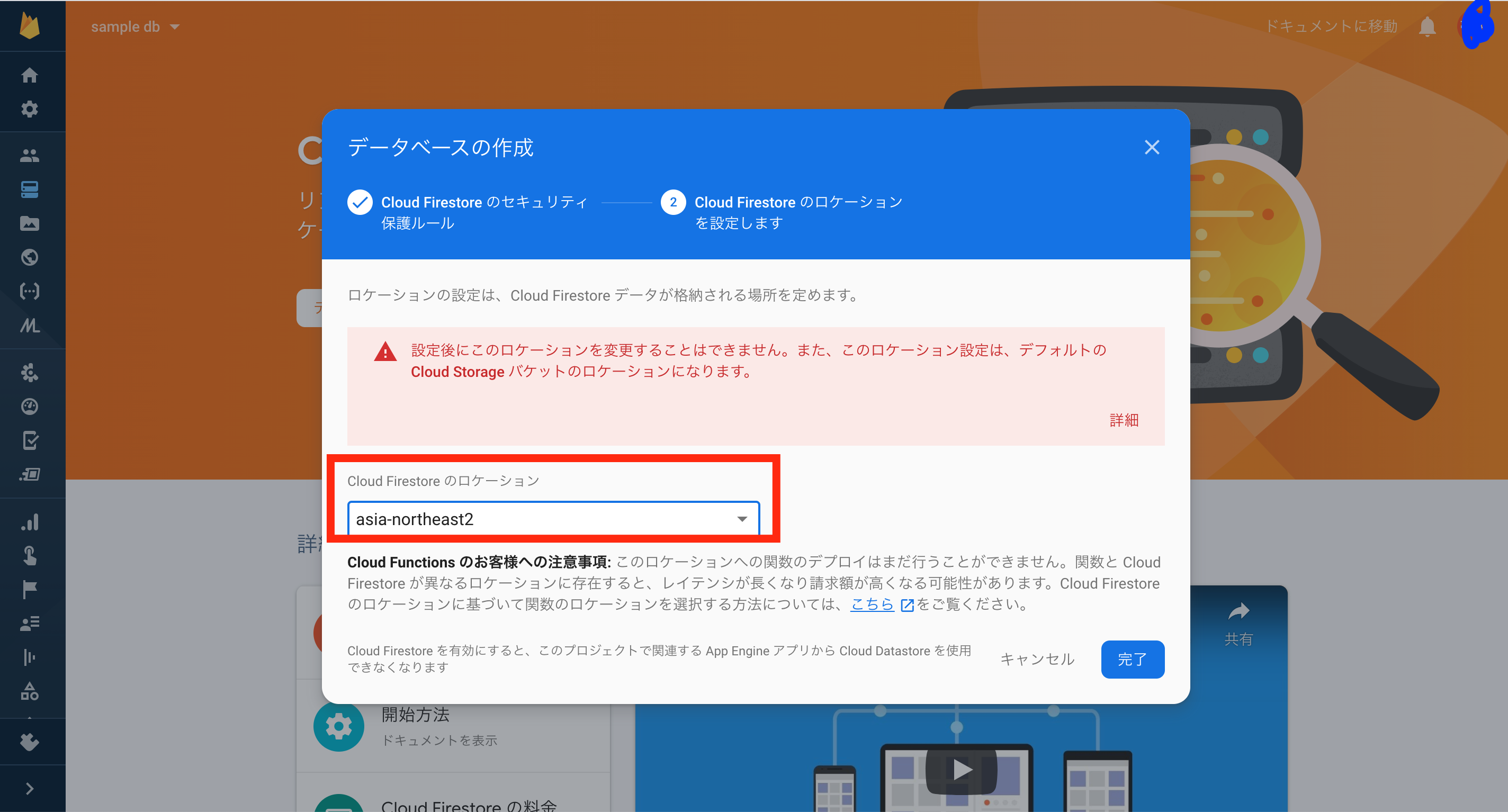
次に、データベースのロケーションを選択します。
ロケーションは、データを利用するユーザーとサービス近いほどレイテンシが小さくなります。
あなたが日本のユーザーをアプリケーションのターゲットにしているのなら、asia-northeast1(東京) か asia-northeast1(大阪) を選択すれば無難でしょう。
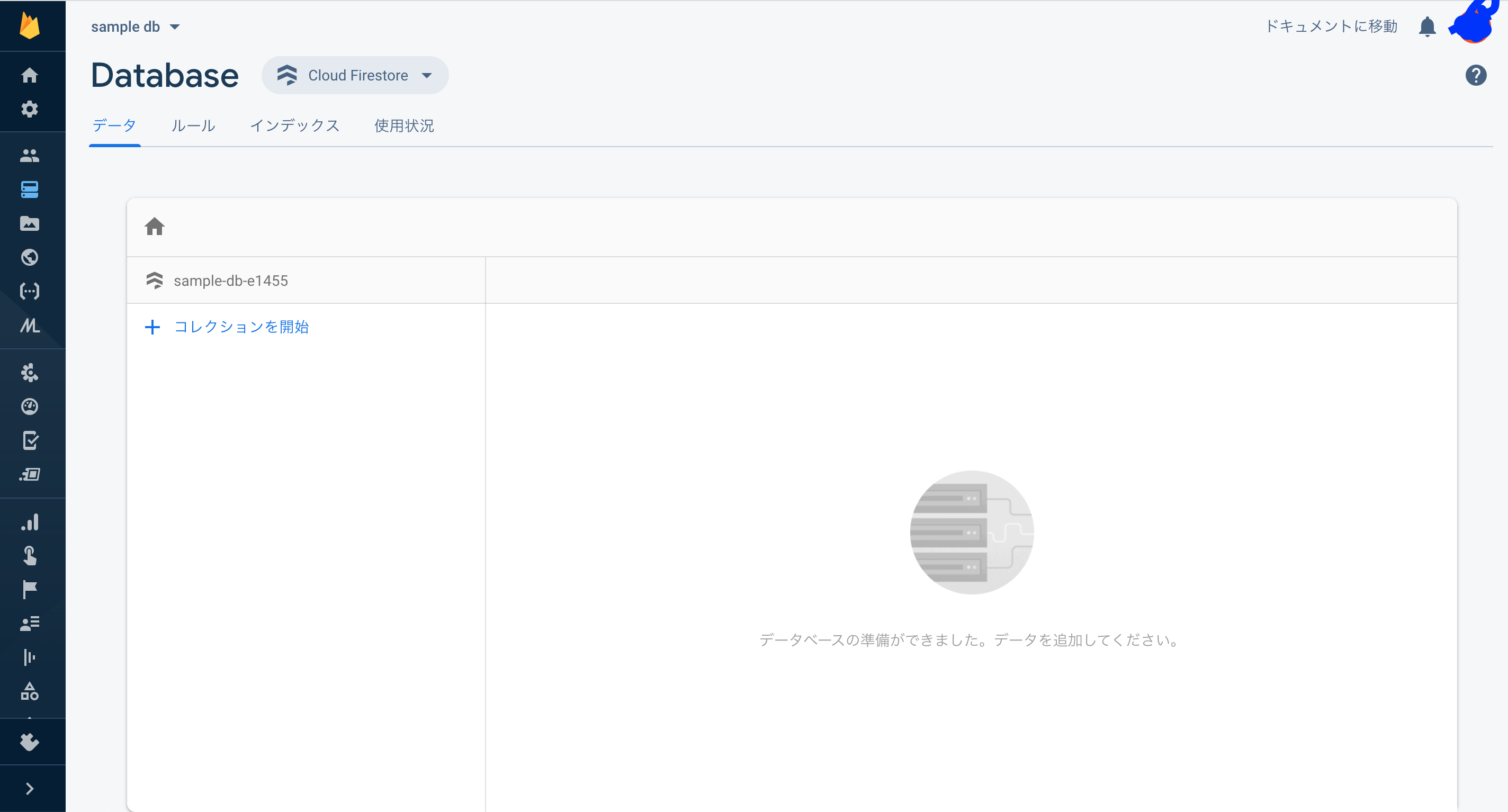
データベースの作成が完了したら、次のような画面が表示されます。
データを追加する
それでは、早速データを追加しましょう。
ますはコレクションを開始します。ここでは、users コレクションを作成します。
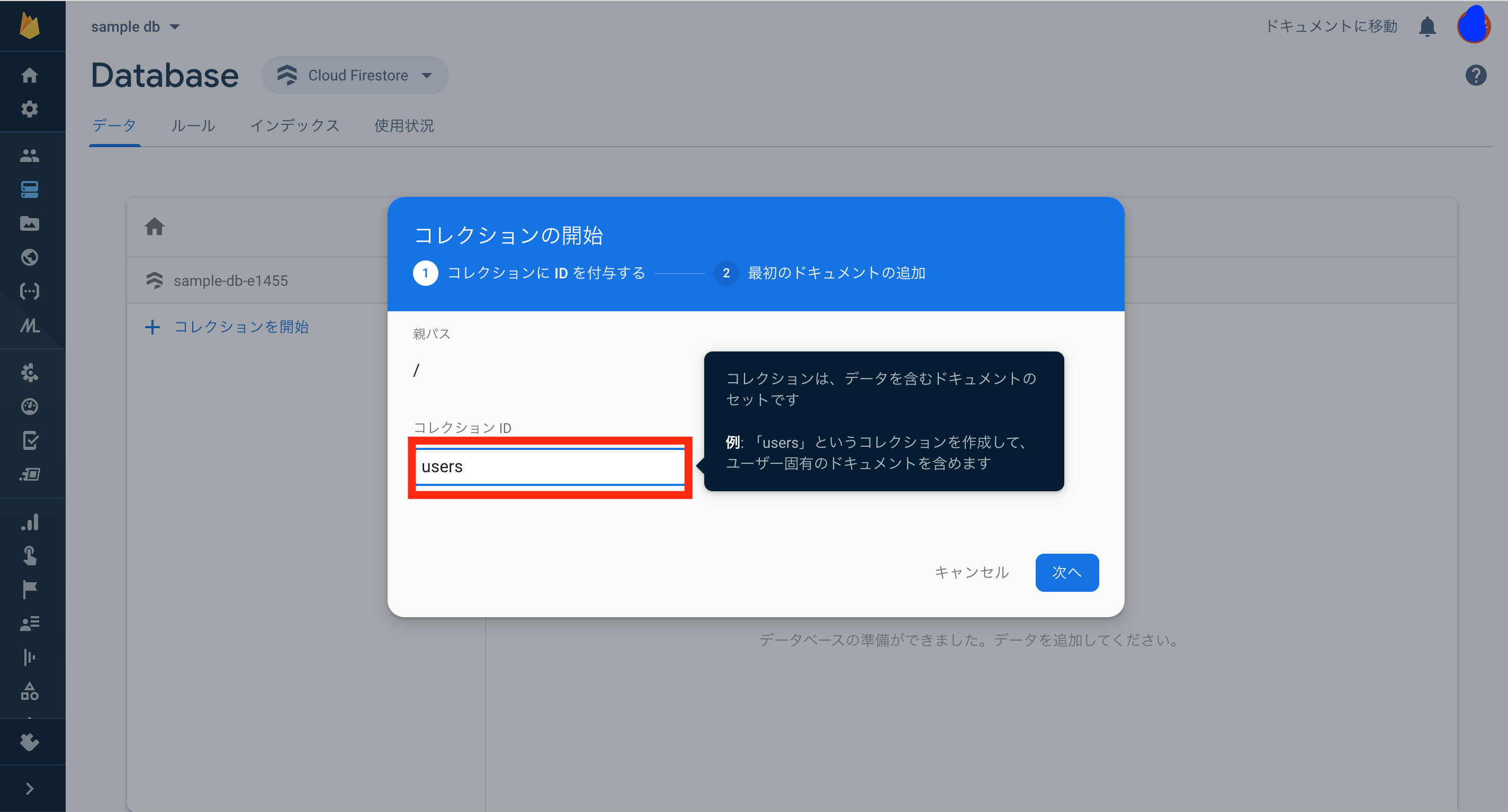
コレクションを作成したら、そのまま最初のドキュメントを追加しましょう。 ドキュメントの ID と、ドキュメントのフィールドを追加します。
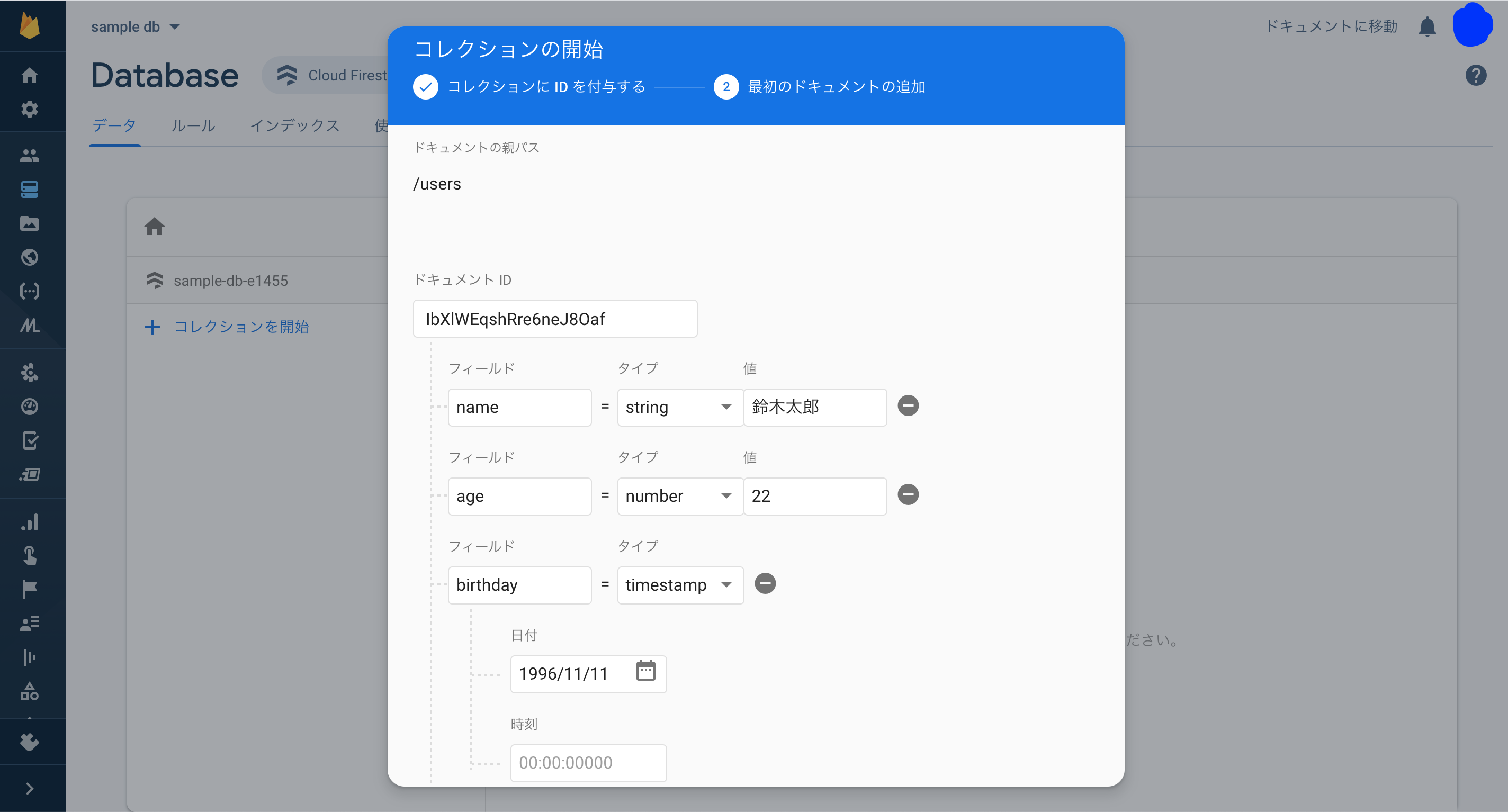
ドキュメントの ID は、なにも入力しなけらばランダムな ID が自動で使用されます。
今回のように users コレクションを作成する場合には、 Firebase Authenticationを利用して作成したユーザーの uid を指定することが一般的です。
uid を使用したらドキュメント ID の一意性が確保されますし。ログインしているユーザーの情報を簡単に取得できます。
ドキュメントのフィールドには、キーとタイプ、値を設定します。
| キー | タイプ | 値 |
|---|---|---|
| name | string | 鈴木太郎 |
ドキュメントの追加が完了したら、データが投入されていることが確認できます。
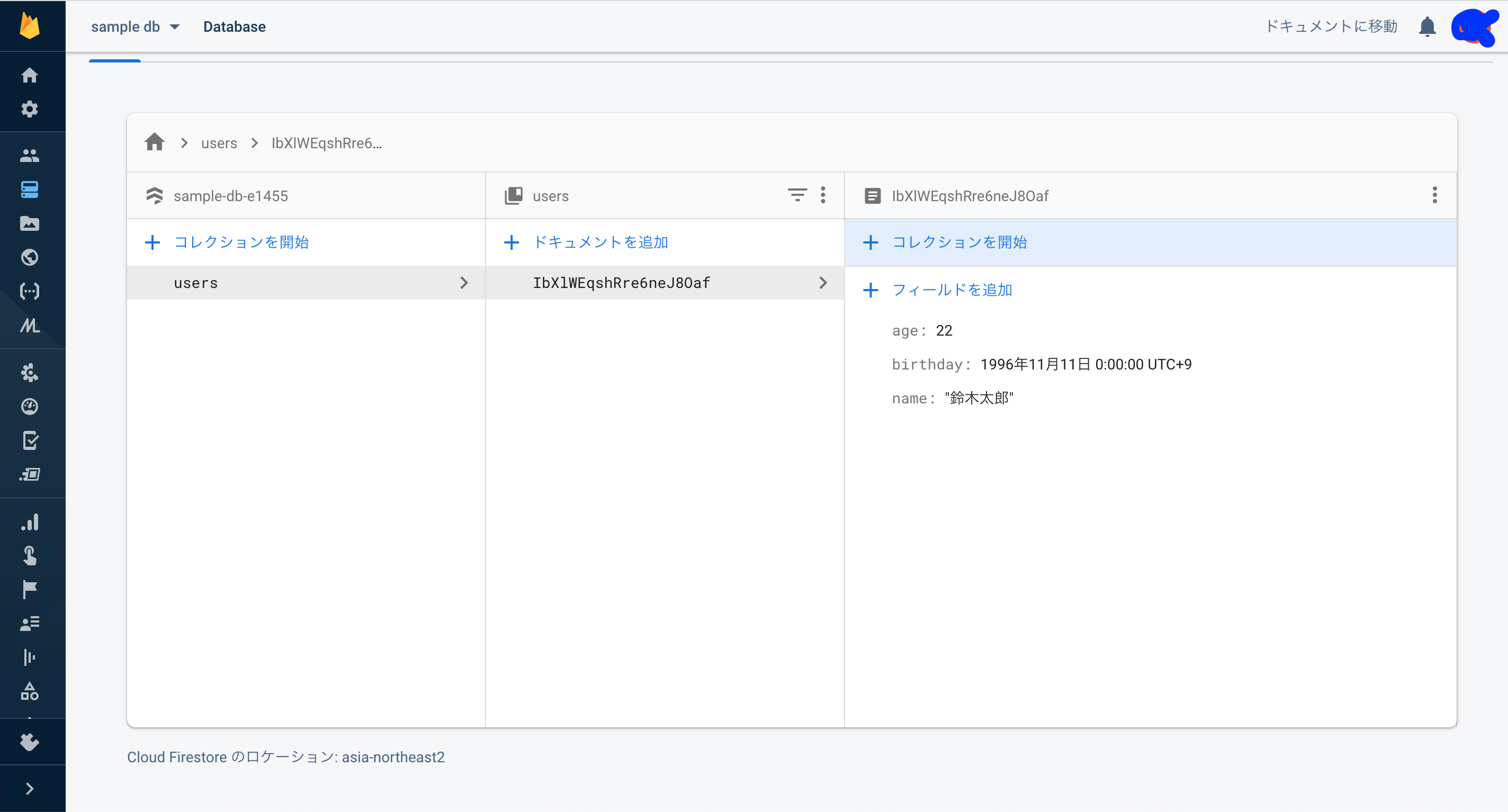
この画面から、さらにコレクションやドキュメントの追加、修正、削除などを行うことができます。
JavaScriptでアプリケーションからFirestoreを利用する
ダッシュボードから FireStore を利用する方法はわかりましたが、おそらくこれはアプリケーションを利用するうえで望んでいる方法ではないでしょう(すべてのアプリケーションの依頼をうけてあなたがデータベースを直接操作するようにしますか?)
Firebase JavaScript SDK を利用してアプリケーション上から操作できるようにしましょう。
開発環境の設定
まずは、アプリケーション上で FireStore を使えるようにするための設定をします。
Firebaseライブラリの追加
<script> タグから Firebase と Firestore のライブラリをアプリケーションに追加します。
<script src="https://www.gstatic.com/firebasejs/7.2.3/firebase-app.js"></script>
<script src="https://www.gstatic.com/firebasejs/7.2.3/firebase-firestore.js"></script>または、npm からパッケージをインストールします。
npm install firebasenpm を利用した場合には、インストールしたパッケージを import しましょう。
import firebase from 'firebase/app'
import 'firebase/firestore'Firestoreを初期化する
API キーなどをセットして、Firebase を初期化します。
Firestore は firebase.firestore() の名前空間から使用できます。
if (!firebase.apps.length) {
firebase.initializeApp(
{
apiKey: process.env.VUE_APP_APIKEY,
authDomain: process.env.VUE_APP_AUTHDOMAIN,
databaseURL: process.env.VUE_APP_DATABASEURL,
projectId: process.env.VUE_APP_PROJECTID,
storageBucket: process.env.VUE_APP_STORAGEBUCKET,
messagingSenderId: process.env.VUE_APP_MESSAGINGSENDERID,
appId: process.env.VUE_APP_APPID,
measurementId: process.env.VUE_APP_MEASUREMENTID
}
)
}
const db = firebase.firestore()ドキュメントを追加する
これで Firestore が使えるようになったので、早速基本の CRUD 操作からやっていきます。 まずは、ダッシュボード上で行ったようにドキュメントを追加します。
IDを指定してドキュメントを追加
ID を指定してドキュメントを追加するには、ドキュメントのリファレンスを作成してから set() メソッドを使用します。set() メソッドは、ドキュメント ID がすでに存在する場合はドキュメントの更新を行い、存在しないドキュメント ID が渡された場合そのドキュメント ID で新規作成をします。
cosnt db = firebase.firestore()
// ログインしているユーザーの情報を取得します。
const user = firebase.auth().currentUser()
// ユーザーコレクションへのリファレンスを作成します。
const userRef = db.collection('user')
// ドキュメントIDにはログインユーザーのuidを指定します。
// setの引数にはJavaScriptのオブジェクトの形式でデータを渡します。
userRef.doc(user.uid).set({
name: '鈴木太郎',
age: 22,
birthday: new Date('1996-11-11') // timestampe型にはDateオブジェクトを渡します。
createdAt: db.FieldValue.serverTimestamp() // サーバーの時間をセットすることもできます。
})
.then(() => // 処理が成功したとき)
.catch(e => // エラーが発生したとき)IDを自動で割り当ててドキュメントを追加
ID を自動で割り当ててドキュメントを追加するには、2 つの方法があります。
- set()
- add()
なお 2 つの方法は完全になど価であり、どちらか好みの方法を利用できます。
set()を利用する
1 つ目の方法は、ID を指定して追加する方法と同じく、set() を利用します。
単純に、doc() に何も渡さなければ、自動的に ID が割り当てられます。
cosnt db = firebase.firestore()
const userRef = db.collection('user')
// doc()の引数にはなにも渡しません
userRef.doc().set({
name: '鈴木太郎',
age: 22,
birthday: new Date('1996-11-11')
createdAt: db.FieldValue.serverTimestamp()
})
.then(() => // 処理が成功したとき)
.catch(e => // エラーが発生したとき)add()を利用する
add() を利用しても同じようにドキュメントを作成できます。
cosnt db = firebase.firestore()
const userRef = db.collection('user')
// doc()の引数にはなにも渡しません
userRef.add({
name: '鈴木太郎',
age: 22,
birthday: new Date('1996-11-11')
createdAt: db.FieldValue.serverTimestamp()
})
.then(() => // 処理が成功したとき)
.catch(e => // エラーが発生したとき)なおドキュメント作成時に存在しないコレクションが指定された場合には、そのコレクションも同時に作成します。
ドキュメントを更新する
ドキュメントを更新するには、以下の 2 つの方法があります。
- update()
- set()
この 2 つの方法は細部が異なるので見ていきましょう。
update()を利用する
ドキュメント全体を上書きせずに一部のフィールドを更新するには、update() メソッドを利用します。
cosnt db = firebase.firestore()
const userRef = db.collection('user')
// ログインしているユーザーの情報を取得します。
const user = firebase.auth().currentUser()
// ageフィールドのみを更新します
userRef.doc(user.uid).updaete({
age: 24,
})
.then(() => // 処理が成功したとき)
.catch(e) = // エラーが発生したとき)set()を利用する
set() メソッドは前述のとおり、すでに存在するドキュメント ID を指定した場合ドキュメントを更新します。
しかし、set() メソッドのデフォルトの動作に注意してください。set() のデフォルトの動作は引数で与えられた値でドキュメントを置き換えるため、もともと持っていたフィールドはすべて失われ新しいオブジェクトの情報だけ残ります。
つまり、update() を利用するのと同じ感覚で下記のように指定した場合異なる動作をするおのでは注意が必要です。
cosnt db = firebase.firestore()
const userRef = db.collection('user')
// ログインしているユーザーの情報を取得します。
const user = firebase.auth().currentUser()
// ageフィールドのみを更新しようとしましたが、もともと持っていたname、birthday、createdAtは失われてしまいます
userRef.doc(user.uid).set({
age: 24,
})
.then(() => // 処理が成功したとき)
.catch(e) = // エラーが発生したとき)// 予期した結果
{
name: '鈴木太郎',
age: 24,
birthDay: timestampオブジェクト,
createdAt: timestampオブジェクト
}
// 実際の結果
{
age: 24
}デフォルトの動作では、変更したくないフィールドも明示的に渡す必要があり、少々不便です。
そこで、一部のフィールドだけを更新したいときは、SetOptions を第 2 引数に渡し、merge パラメータに true を指定します。
cosnt db = firebase.firestore()
const userRef = db.collection('user')
// ログインしているユーザーの情報を取得します。
const user = firebase.auth().currentUser()
// ageフィールドのみを更新しようとしましたが、もともと持っていたname、birthday、createdAtは失われてしまいます
userRef.doc(user.uid).set({
age: 24,
}, { merge: true })
.then(() => // 処理が成功したとき)
.catch(e) = // エラーが発生したとき)ドキュメントを削除する
ドキュメントの削除には、delete() メソッドを利用します。
cosnt db = firebase.firestore()
const userRef = db.collection('user')
// ログインしているユーザーの情報を取得します。
const user = firebase.auth().currentUser()
userRef.doc(user.uid).delete()
.then(() => // 処理が成功したとき)
.catch(e) = // エラーが発生したとき)単一のドキュメントを取得する
単一のドキュメントを取得するには、get() メソッドを利用します。
cosnt db = firebase.firestore()
const userRef = db.collection('user')
// ログインしているユーザーの情報を取得します。
const user = firebase.auth().currentUser()
const result = []
userRef.doc(user.uid).get()
.then(doc => {
if (doc.exists) {
result.push({
id: doc.id,
...doc.date() // doc.data()からデータのオブジェクトを取得できます。
})
} else {
console.log('結果は空です')
}
})
.catch(e => // エラーが発生したとき )get() が成功したら、doc.exists() でドキュメントが空でないかチェックします。
ドキュメントが存在したのならば、doc.id で ID を、doc.data() からデータのオブジェクトを取得できます。
クエリを発行する
今週はここまで🤔。


